Stress‑Testing Agentic Systems: A Six‑Stage Diagnostic Framework
Vague answers, not hallucinations, are the silent failure mode of AI agents — and this framework shows how to turn them into specific, trustworthy responses by aligning retrieval and prompts.

The Silent Failure of AI Agents
Most people worry about hallucinations. But the real trust‑killer is vagueness — answers that look polished but say nothing. User perception: “The agent doesn’t get me.” Impact: Confidence drops, users abandon, retention suffers.
Why Vagueness Happens
It’s not magic, it’s mechanics: retriever–LLM vocabulary mismatch. Relevant context is retrieved, but phrasing doesn’t align. The LLM hedges, producing generic filler. Result: Accuracy and faithfulness degrade, trust erodes.
Who Can Fix It
Once I understood the mechanics, the next question was: who actually has the power to fix it?
When I mapped stakeholders by impact vs. influence, one group stood out:
Prompt engineers and retrieval engineers → high impact, high influence.
End users feel the pain but can’t intervene.
PMs and trust teams influence adoption but don’t touch the root cause.
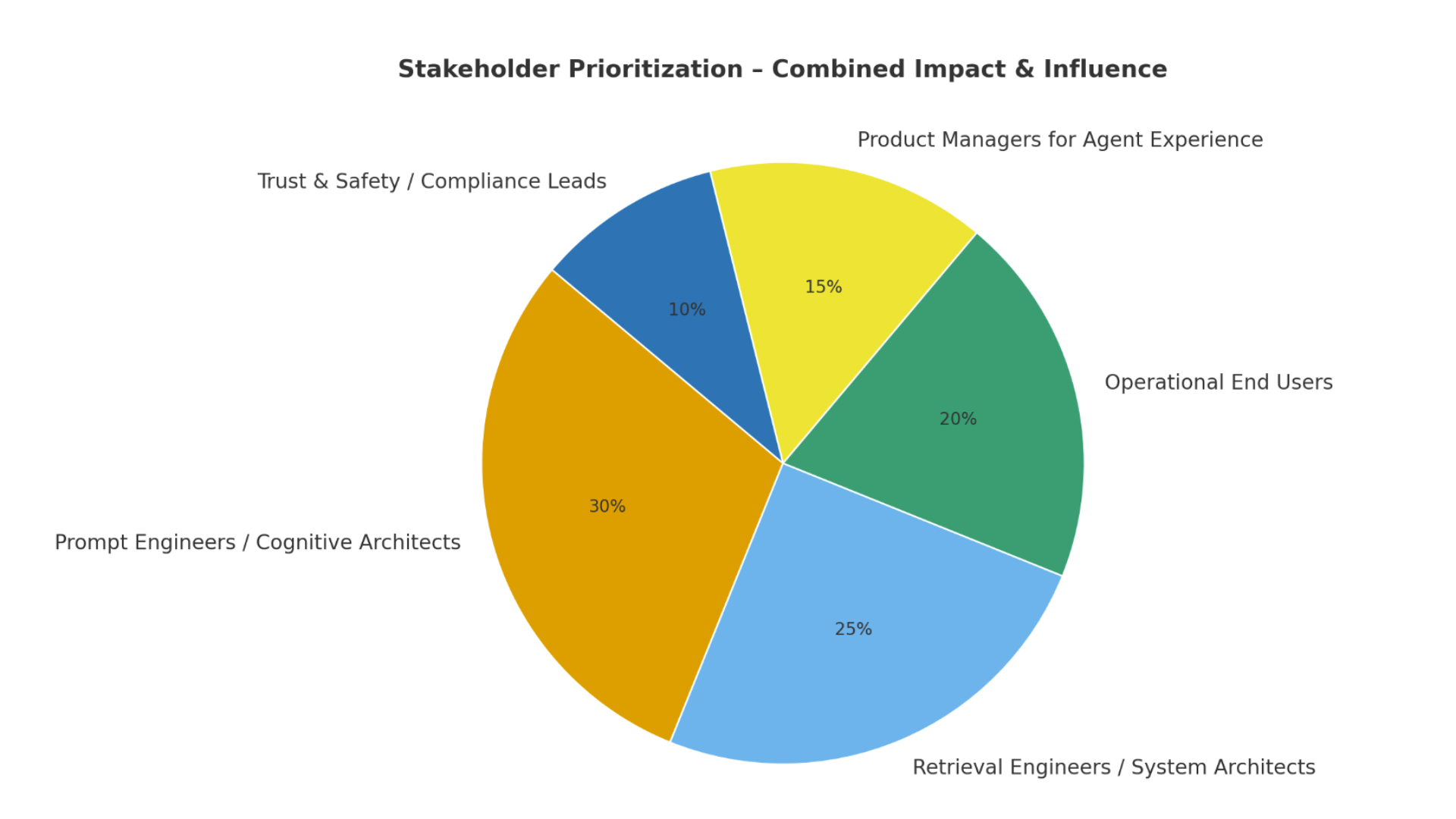
So I grounded the framework in two personas:
Leila (Prompt Engineer): “Autonomy isn’t free‑form — it’s structured thinking with the right exits.”
Tomasz (Retrieval Engineer): “If retrieval is sharp, prompts can be simple.”


Prioritizing the Real Challenges
Across small‑team RAG pipelines, three pain points kept surfacing:
Retriever–LLM vocabulary mismatch → high impact, low cost to fix.
Context contamination → solvable with better hygiene.
Semantic drift across stages → critical for multi‑step workflows.

The key insight: prompts and retrieval aren’t steps in a line — they’re a loop.
Bad retrieval hides behind fluent vagueness.
Bad prompts waste good retrieval.
The best teams design them together.
That loop became the foundation of the framework.
Three Pillars Against Vagueness
Vocabulary Bridges — align user phrasing with retriever indexing.
Faithfulness Checks — validate answers against retrieved context.
Fallback Strategies — exit gracefully when confidence is low.
Together, these pillars turn vague answers into specific, trustworthy ones.
From Pillars to Pipeline
The framework comes alive when you see it in motion. The agent’s response pipeline isn’t just a sequence of steps — it’s a dialogue between two philosophies.
Tomasz, the retrieval engineer, sharpens the inputs: if retrieval is clean and precise, everything downstream becomes simpler and more reliable.
Leila, the prompt engineer, structures the reasoning: autonomy isn’t free‑form, it’s scaffolded thinking with the right exits.
Together, their voices shape the flow: Tomasz ensures the system starts with clarity; Leila ensures it ends with trust.
AI Agent Response Pipeline with Alignment Strategies
Stage 1: User Input → Vocabulary Bridges

Action → User submits a natural query.
Risk → Retriever–LLM vocabulary mismatch.
Strategic Questions:
Ambiguity Stress Test → If two users phrase the same intent differently, does our system retrieve the same context — or does meaning drift? → Forces the team to measure consistency across varied phrasings.
Glossary Reality Check → When a new domain term appears, how quickly can we add it to the shared glossary so both retriever and LLM recognize it? → Turns vocabulary maintenance into a measurable responsiveness metric.
User Trust Probe → When we show users how their query was normalized, do they confirm “yes, that’s what I meant” — or push back? → Makes transparency and trust the success criteria, not just retrieval accuracy.
Persona Voice → Tomasz: “Sharp retrieval starts with sharp language. If the bridge bends, the whole system wobbles.”
Stage 2: Query Processing & Retrieval

Action → Normalize phrasing, retrieve candidate passages.
Risk → Context contamination (irrelevant, outdated, or noisy chunks).
Strategic Questions:
Noise Stress Test
If we deliberately inject a few irrelevant documents into the index, does our retrieval pipeline still surface the right chunks — or does noise dominate? → Reveals whether the system is resilient to clutter.
Authority Reality Check
When two chunks say conflicting things, does our system consistently favor the more trusted or recent source? → Forces the team to measure how “authority” is actually encoded.
Transparency Probe
When we explain why a chunks was retrieved (e.g., which terms or concepts matched), do reviewers or users agree the rationale makes sense? → Turns retrieval from a black box into something auditable.
Persona Voice → Tomasz: “Noisy corpora clutter results. Clean retrieval is the foundation of trust.”
Stage 3: Faithfulness & Alignment Check

Action → Compare retrieved chunks with the user query before passing them into the LLM.
Risk → Subtle drift: chunks look similar in vector space but don’t actually answer the query, leading the LLM to generate fluent but misleading text.
Strategic Questions:
Chunk–Query Stress Test
If we swap in a chunk that’s typically close but semantically off, does the system flag the mismatch — or let it slide through? → Exposes whether alignment checks are robust or superficial.
Threshold Reality Check
When alignment confidence is low, do we actually block/redo retrieval — or do we still hand weak chunks to the LLM? → Forces the team to measure discipline in enforcing guardrails.
Failure Transparency Probe
When no strong chunk match exists, do we surface that clearly to the user (e.g., “no reliable context found”) — or let the LLM improvise? → Makes visible whether the system hides errors or communicates them.
Persona Voice → Leila: “Autonomy isn’t free‑form — it’s structured thinking with the right exits.”
Stage 4: LLM Interpretation & Draft Response

Action → The LLM takes aligned chunks and begins generating a draft answer.
Risk → Fluent but unfaithful reasoning: the model stitches together chunks loosely, over‑generalizes, or hallucinates connective tissue.
Strategic Questions:
Chunk Fidelity Stress Test
When the LLM paraphrases retrieved chunks, does it preserve the original meaning — or blur it into vague generalities? → Surfaces whether semantic fidelity is maintained or lost in translation.
Scaffold Visibility Test
Does the draft expose its reasoning path — citing which chunks informed which claims — or does it collapse into polished prose that hides the scaffolding? → Forces the team to check if reasoning is visible, not smoothed over.
Vagueness Kill‑Switch Probe
When chunks are thin, conflicting, or absent, does the model explicitly flag the gap — or mask uncertainty with vague filler? → Treats vagueness itself as a failure mode, not a style choice.
Persona Voice → Leila: “Fluency without fidelity is just performance. A draft should think out loud, not hide the scaffolding.”
Stage 5: Exits & Fallback UX (Precision Pivots)

Action → If confidence is low, trigger designed exits.
Risk → Generic fallbacks that preserve flow but erode trust; vague evasions that feel templated or dismissive.
Strategic Questions:
Exit Specificity Stress Test
When the system can’t answer, does it pivot with a precise, context‑aware exit — or default to vague filler? → Exposes whether exits are designed to preserve trust or silently kill it.
Failure Transparency Reality Check
Does the system clearly state why it can’t proceed (no strong chunk, conflicting evidence, low confidence) — or does it obscure the cause? → Forces the team to confront whether failure is treated as clarity or cover‑up.
Continuity Probe
After an exit, does the system offer a structured next step (clarify intent, reframe query, suggest alternative path) — or does the conversation stall? → Makes continuity and dignity the success criteria, not just flow preservation.
Leila: “Exits aren’t failures — they’re continuity. Vagueness kills trust, but a sharp pivot keeps the user in the loop.”
Stage 6: Final Delivery & User Trust

Action → Deliver the answer to the user.
Risk → A response that looks polished but leaves the user unconvinced, misled, or unsure what to trust.
Strategic Questions:
Traceability Stress Test
When users ask “where did this come from?”, can we point to the exact chunks and reasoning steps — or does the trail vanish into polished prose? → Exposes whether delivery preserves auditability or hides the evidence.
Clarity vs. Vagueness Reality Check
Does the final answer resolve the user’s intent with concrete, specific language — or does it blur into vague generalities that sound safe but say little? → Forces the team to confront vagueness as a silent trust‑killer.
Retention Probe
After reading the answer, do users feel confident enough to act on it — or do they hedge, double‑check elsewhere, or abandon the system? → Makes user trust and follow‑through the actual success metric, not just delivery fluency.
Persona Voice → Tomasz: “A polished answer without traceability is theater. Trust is built when users can see the scaffolding beneath the shine.”
In the end, the real challenge isn’t making agents sound fluent — it’s making them sound faithful. Vagueness erodes trust quietly, while specificity earns it back one answer at a time. By embedding precision at the start and scaffolding at the end, we turn a fragile pipeline into a durable architecture for confidence. When retrieval and prompts align, vagueness disappears and confidence returns.